Evolution Meets Diffusion: Efficient Neural Architecture Generation
Introduction
Neural Architecture Search (NAS) has gained widespread attention for its transformative potential in deep learning model design. However, the vast and complex search space of NAS leads to significant computational and time costs. Neural Architecture Generation (NAG) addresses this by reframing NAS as a generation problem, enabling the precise generation of optimal architectures for specific tasks. Despite its promise, mainstream methods like diffusion models face limitations in global search capabilities and are still hindered by high computational and time demands. To overcome these challenges, we propose Evolutionary Diffusion-based Neural Architecture Generation (EDNAG), a novel approach that achieves efficient and training-free architecture generation. EDNAG leverages evolutionary algorithms to simulate the denoising process in diffusion models, using fitness to guide the transition from random Gaussian distributions to optimal architecture distributions. This approach combines the strengths of evolutionary strategies and diffusion models, enabling rapid and effective architecture generation. Extensive experiments demonstrate that EDNAG achieves state-of-the-art (SOTA) performance in architecture optimization, with an improvement in accuracy of up to 10.45%. Furthermore, it eliminates the need for time-consuming training and boosts inference speed by an average of 50×, showcasing its exceptional efficiency and effectiveness.
Contributions
- Propose a novel Evolutionary Diffusion-based framework for Neural Architecture Generation (EDNAG), which simulates the denoising process in diffusion models within an evolutionary paradigm.
- Introduce a Fitness-guided Denoising (FD) strategy, which utilizes fitness instead of trained networks to generate offspring architecture samples from previous ones, achieving the first network-free neural architecture generation approach.
- Conduct extensive experiments to demonstrate the SOTA performance of EDNAG in architecture generation with significantly fewer computational resources, as well as its outstanding adaptability and transferability.
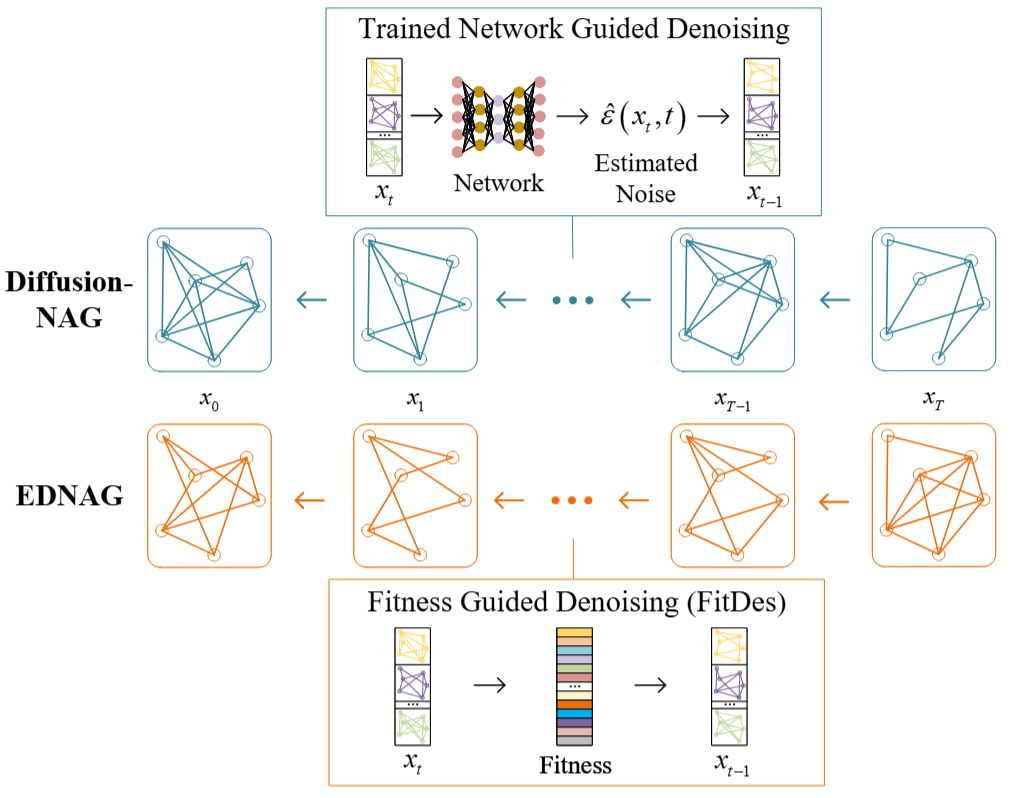
Methods
The core innovation of EDNAG is its simultaneous enhancement of both efficiency and generation
quality. Specifically, we
introduce evolutionary algorithms to simulate the denoising process within diffusion models.
Furthermore, we propose a
Fitness-guided Denoising (FD) strategy, which generates new architectures from previous ones at each
denoising
iteration. Each newly generated architecture can be represented as a weighted summation of prior
samples, where superior
architectures are assigned higher weights and thus exert greater influence. As a result,
architecture samples
progressively evolve toward high-fitness subspaces through multiple FD-guided denoising iterations,
ultimately yielding
high-performing and globally optimal neural architectures.
In particular, EDNAG leverages a neural predictor for task-specific neural architecture generation,
serving as a
dataset-aware fitness evaluator that guides the conditional generation process within the FD
strategy. Notably, the FD
strategy removes the reliance on score networks used in traditional diffusion models during the
denoising process,
enabling network-free neural architecture generation and substantially improving generation
efficiency.
Derivations
For diffusion models like DDIM, in the forward process, we blend data with Gaussian noise, perturbing the original data x0 to the final diffused data xT as Eq (1).
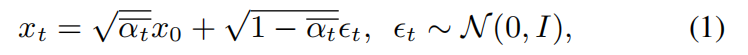
In the reverse process, DDIM removes the noise from the randomly initialized data step by step,
which is represented as Eq (2).
Traditional DDIM leverages a neural network ϵθ to predict perturbed
noise ϵˆθ (xt, t) at time step t, guiding the denoising process. By iteratively repeating this
denoising process in Eq (2), DDIM progressively generates the final samples.

For each denoising iteration, let xˆ0 denotes the predicted x0 in Eq (2).
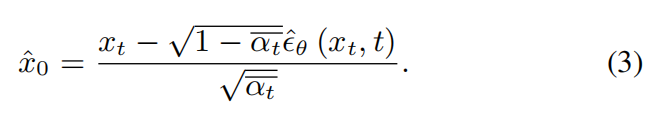
With Eq (3), the denoising process can be transformed into Eq (4).
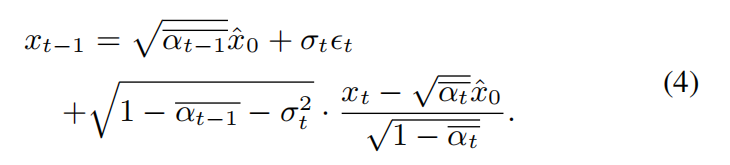
Therefore, to perform the denoising process from xt to xt-1, it is only necessary to determine the
predicted optimal architectures xˆ0 based on xt, αt and t.
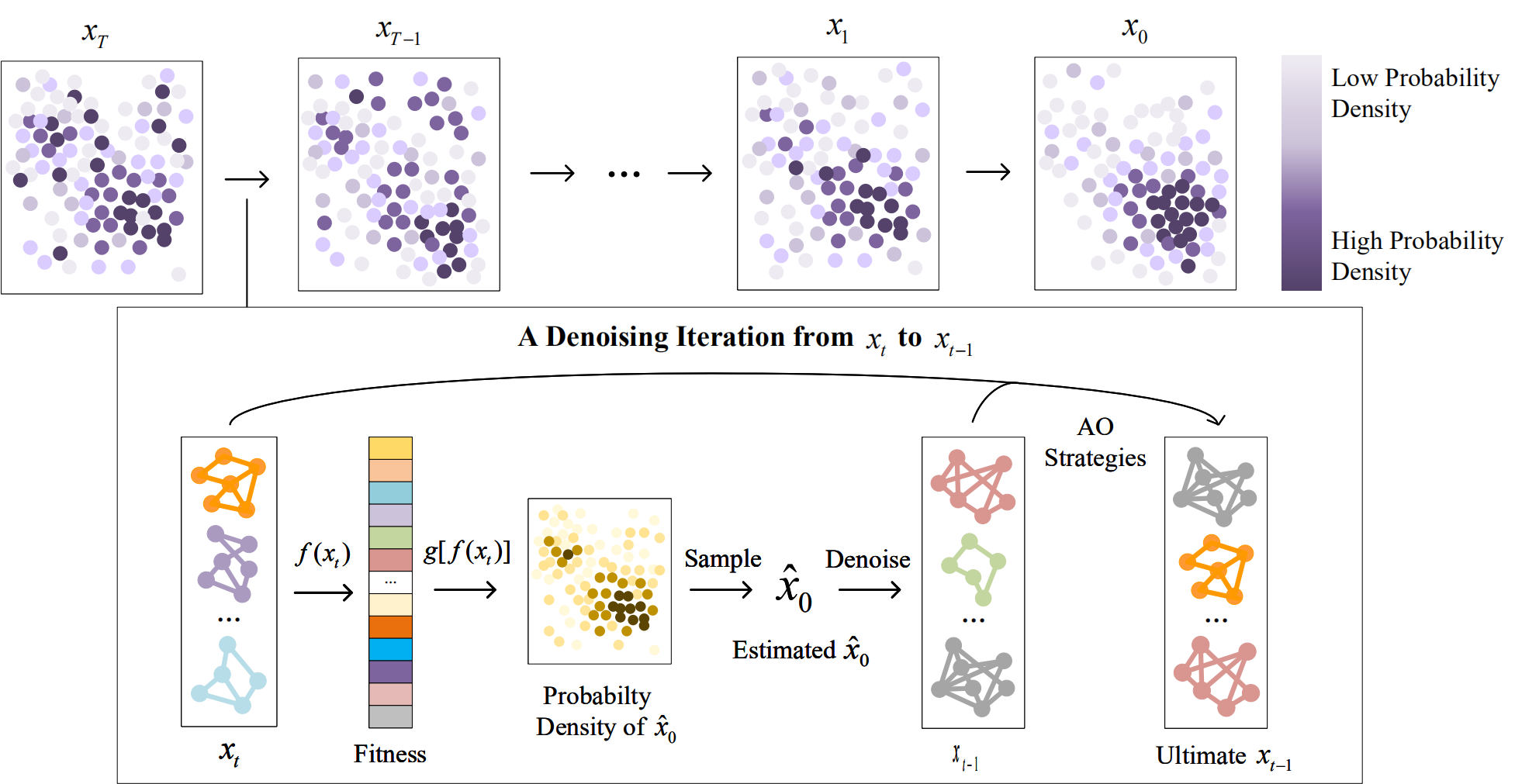
To estimate xˆ0, Fitness-guided Denoising (FD) strategy maps the distribution of xt to the
distribution of xˆ0 with fitness guidance. Specifically, we view the denoising process of DDIM as
the evolutionary process of GAs, both transforming samples from an initial random Gaussian
distribution to an ultimate optimal distribution progressively [47]. We consider that individuals
with higher fitness are more likely to be retained during evolution, resulting in a higher
probability of appearing in the final samples xˆ0. Therefore, higher fitness corresponds to a higher
probability density in xˆ0. We model this relationship as a mapping function g(x), which maps the
fitness f(xt) of xt to the probability density p(ˆx0) of xˆ0:
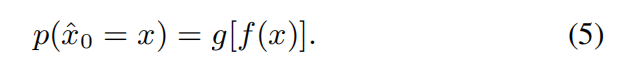
Hence, the optimal architectures xˆ0 can be estimated from the samples xt at time step t and their fitness f(xt), as detailed in Eq (6).
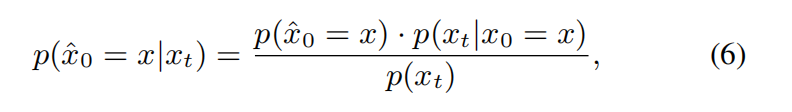
where p(xt|x0 = x)is s derived from the diffusion process described by Eq (1), as shown in Eq (7).
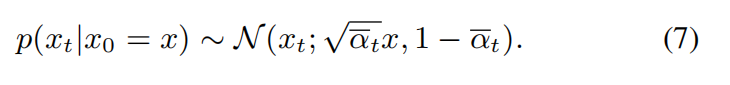
We further define xt as the previous samples consisting of N architectures, where xt = [x1t , x2t, . . . , xNt]. Combining Eq (6) and (7), xˆ0 can be estimated as follows.
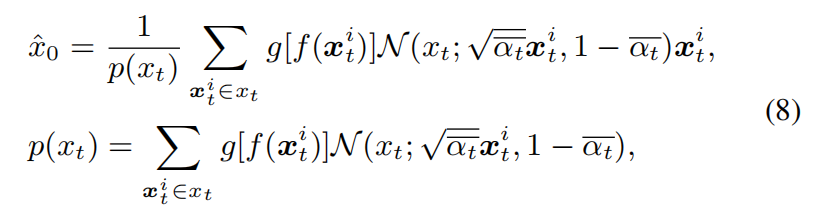
where p(xt) actually serves as a regularization term. In fact, xˆ0 can be regarded as the weighted summation of each neural architecture xt^i in samples xt, where architectures with higher fitness have a greater influence on xˆ0. Finally, with Eq (4) and (8), we can denoise from xt to xt-1 as Eq (9).
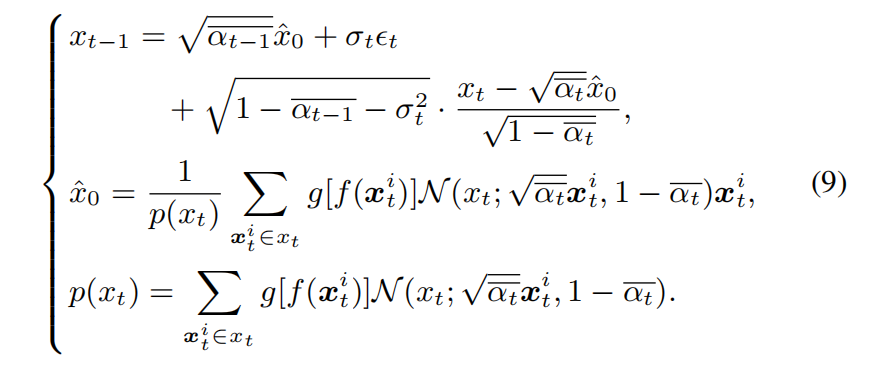
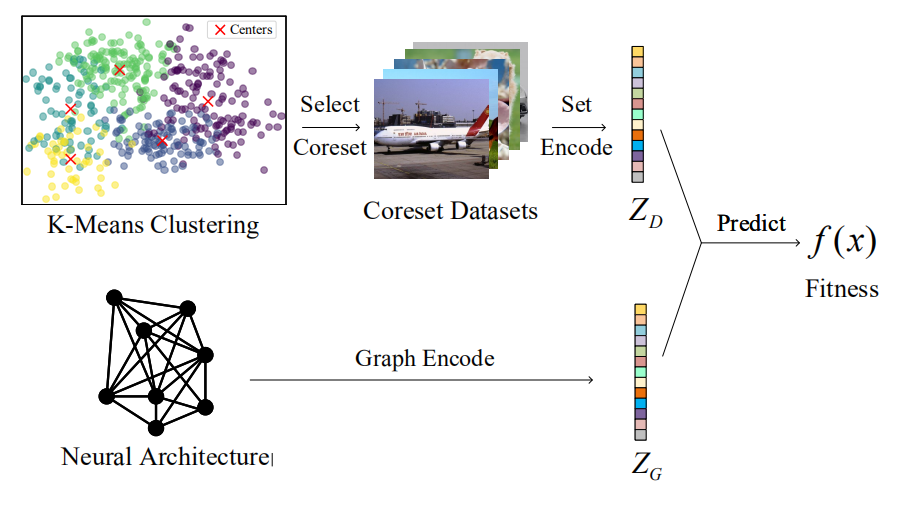
For fitness evaluation, we utilize a neural predictor to evaluate the fitness of each architecture. The entire process is detailed in the following figure.

Our predictor comprises coreset selection, dataset encoding, architecture encoding, and accuracy prediction modules, which is detailed in the following figure.
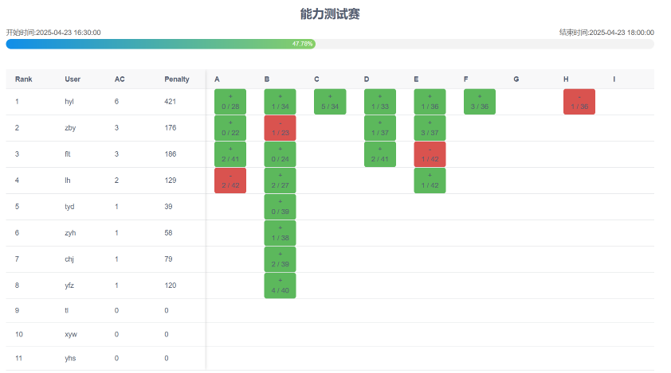
Experiments
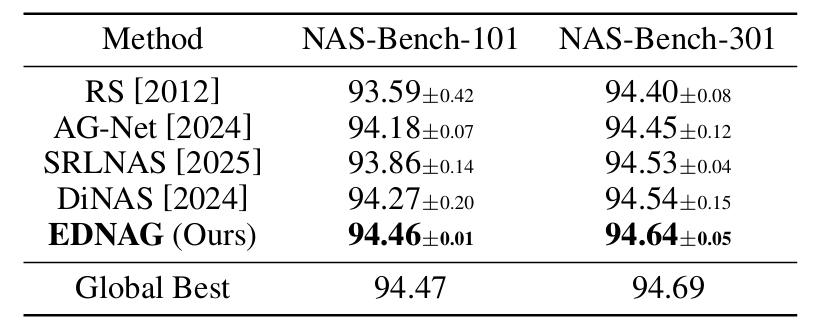
NAS-Bench-101 & NAS-Bench-301
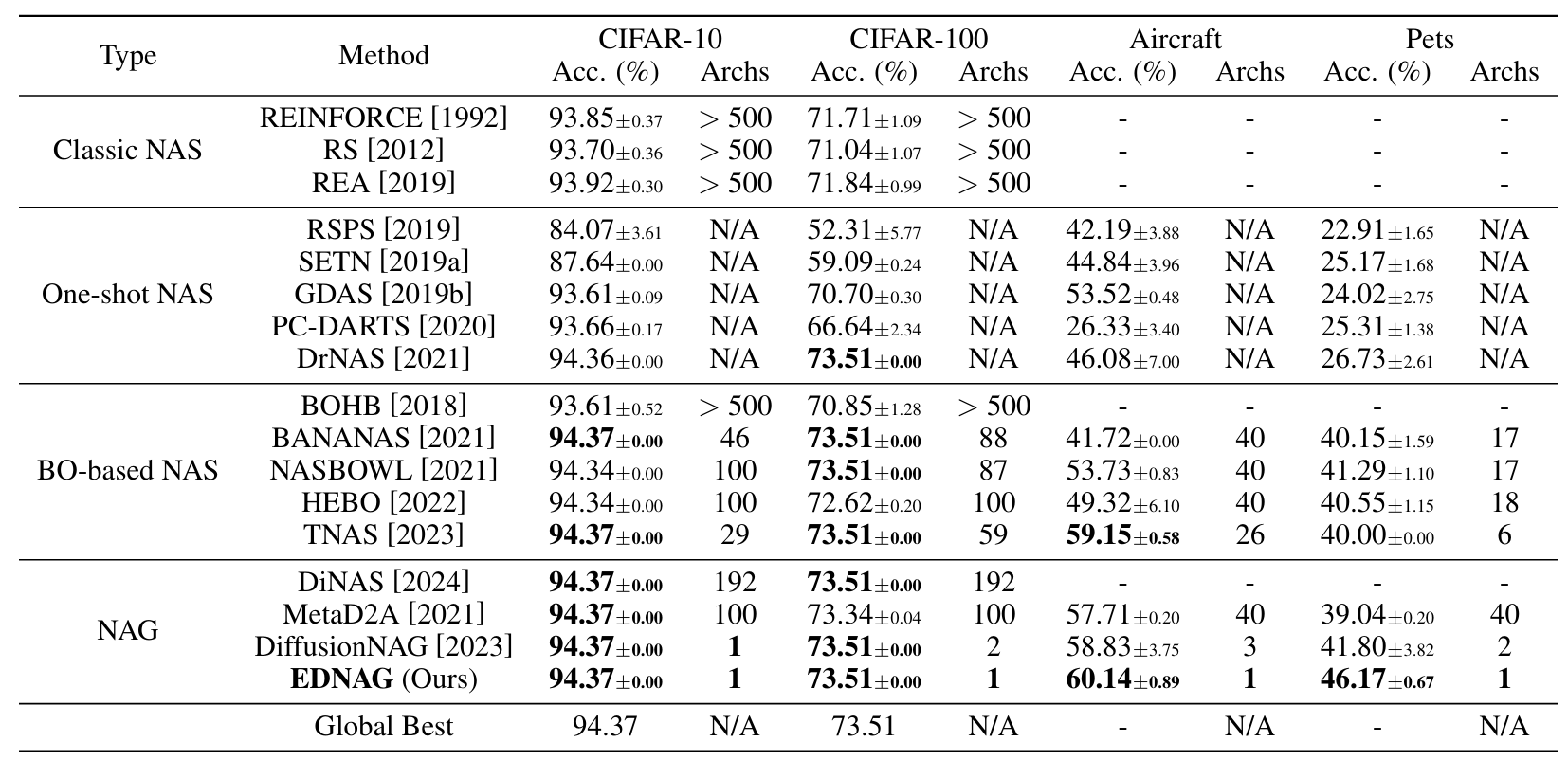
NAS-Bench-201
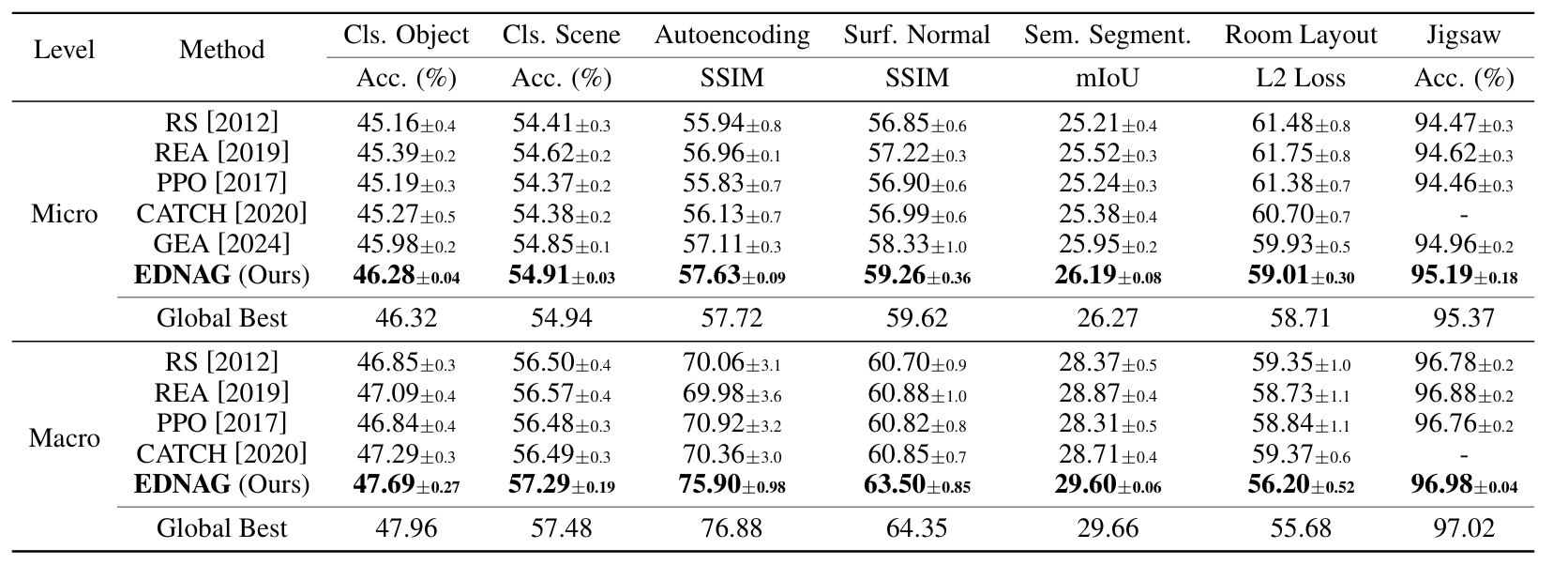
TransNASBench-101
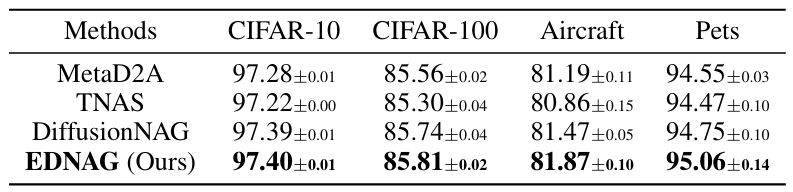
MobileNetV3
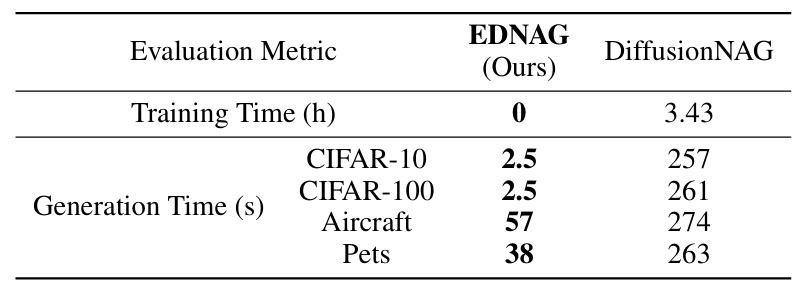
GPU Time Costs